

Newsletter #6: How does DALL.E.2 work?

A few months ago, OpenAI released an image generation AI program called DALL.E.2. The program accepts text prompts and generates images based on them. It is truly amazing to see the accuracy with which it can capture the essence of the text input. It is also a significant step forward in generative AI models. In addition to this, OpenAI has made the images generated by DALL.E.2 available for free use in commercial and personal capacity under the MIT License. I have used it in this newsletter many times and I love it. Here are some of the text prompts and the corresponding images I have generated using the program:

Nuts right? I know. 😄
In this post, we take under the hood to see all the different components that makeup DALL.E.2 and how they work together.
The big picture view
To begin with let’s look at a big picture view of the system:

The text input is passed to a Text Encoder which outputs text embeddings or maps the input to a representational state. You can think of this as converting the input to a set of numbers which can then be used to manipulate the input and draw insights from it.
This input is passed to another model called the Prior, which uses the embeddings and maps them to an image embedding. This will capture the semantic information of the input text.
In the final step, an image decoder will decode the image embedding back to an image.
This is the gist of how the framework behaves. If you just wanted an overview, you can skip the rest of this post. However, if you want to get a deeper understanding of how each of the components works, we will have to look at some of the technical details.
Deep Dive
CLIP
The text and image embedding generated from the first two components use a technology called CLIP or Contrastive Language Image Pre-training. It consists of two neural networks, a text encoder which is a Transformer, and an Image encoder which is a Vision Transformer.
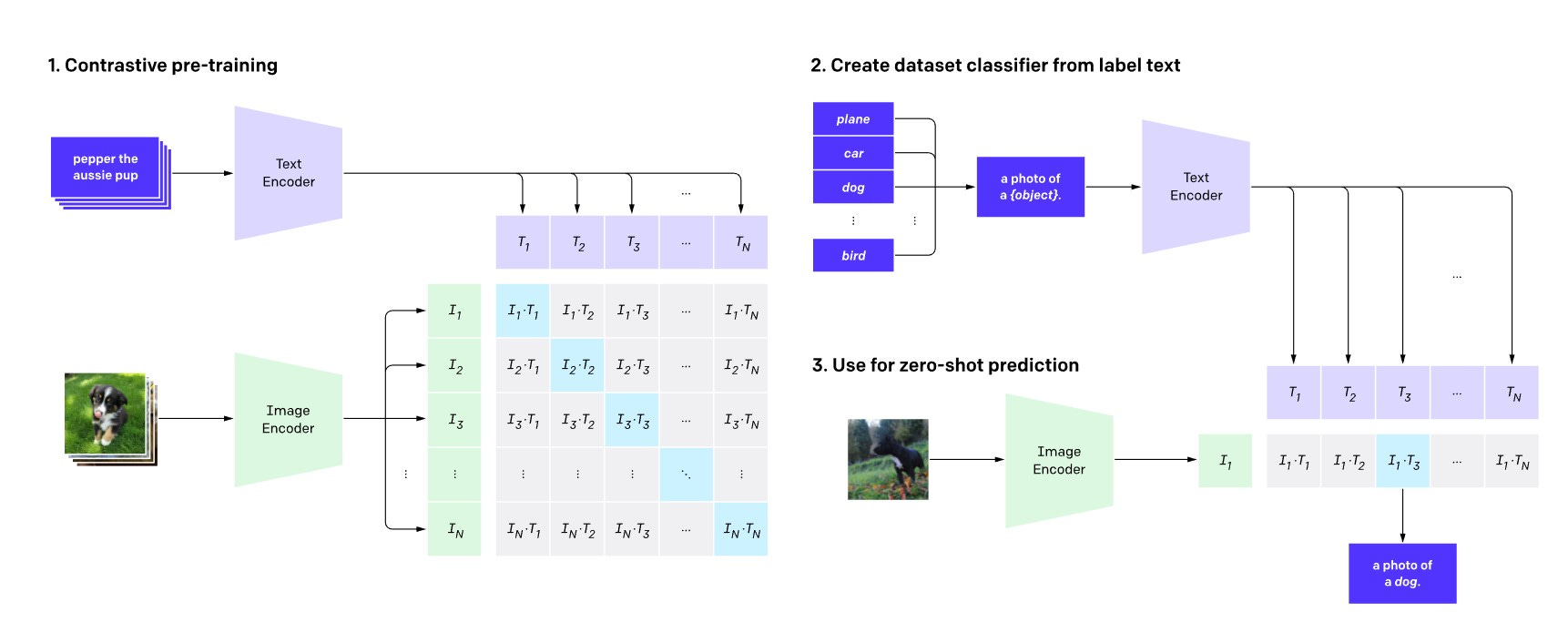
The goal of CLIP is to map matching pairs of text-image on a representation space.
So what does this mean?
The text encoder and the image encoder will output their respective embeddings.
The goal of CLIP is to map them closely in the representation space such that closely matching pairs have a large cosine similarity and loosely matching pairs have low cosine similarity during training.
In simple words, for a text caption, “Dog on a bike”, the image embedding of a “Dog on a bike” will have the highest similarity value, “Dog on a skateboard” will have a lower similarity value, and “Cat in a park” will have lowest similarity value.
Now you might be wondering, how does CLIP generate an embedding for an unseen image?
For example, I might train my CLIP model on cats and dogs and then give input as “A Lion sitting on a skateboard”
Well, CLIP uses something called zero-shot learning to achieve this. Zero-shot or Zero-data learning is defined as follows in the white paper:
“Zero-data learning corresponds to learning a problem for
which no training data are available for some classes or tasks
and only descriptions of these classes/tasks are given”
What does this mean? Essentially, you can train a neural net to recognize digits such that after the training process is complete, given an input of digits, it can output probabilities of it being 0-9, in addition to this, however, using the same neural net, you will be able to classify characters such as A, a, B, b, etc. This is because, for similar problems, the features that the neural net needs to identify are also similar. This is an oversimplification of the concept, but it gives a good bird’s eye view.
Now that we know how we are getting out the word as well as image embeddings, let’s look at how to use them to get our final image.
Diffusion Prior and GLIDE
Okay, one confession here, although I made it look like CLIP generates the image embeddings all by itself, it is not exactly true. The image embeddings are generated with the help of a Diffusion prior. GLIDE, which stands for Guided Language to Image Diffusion for Generation and Editing, and is used for the final image generation, is also based on Diffusion Models, so it is useful to know what they are and how they work.
Diffusion models are transformer based generative models that take a piece of input, add noise to it until it is corrupt and try to reconstruct the photo to its original form. If you recall, CLIP maps text encodings and image encodings. The diffusion prior (The box named Prior in the first diagram) is used to map text encodings of the caption or the inputs, to image encodings of their corresponding images. So even though CLIP forms text-image encoding pairs, the image encoding itself is created by the prior.
Now to the most interesting part of this whole process: Generating images from the embeddings
In a vanilla diffuser, the model starts with random noise. The key insight in the GLIDE algorithm is Guided Diffusion. At each time step, the algorithm also inputs the CLIP embeddings to guide the reconstruction of the image. So, if you have trained the diffuser on a car but you want to generate an “Audi sports car”, the GLIDE algorithm will input the additional Sports Car context at some timesteps. This changes the image from a plain car to a specific car. This is also called the unCLIP model as we are reversing the process of the CLIP model.

Limitations
Even though the DALL.E.2 is impressive in what it can do, it does have certain limitations. One of the things I found while playing with it, is that it cannot render images with text on them. This could be because the model cannot distinguish between what to interpret as is vs what to interpret deeply. Here’s an example where I try to make the program draw Maslow’s hierarchy of needs.

Looking at the image, it is obvious that the terms pyramid, hierarchy, and oil painting are modeled correctly, however it did not resolve ‘Maslow’ properly. I also tried with the input string ““ ‘Maslow pyramid of needs’ as an abstract oil painting ”“ to check if it can identify ‘Maslow pyramid of needs’ as a single entity, but it failed for this input as well.
Another problem is with reinforcing the bias already present in our daily communication. Since DALL.E.2 was trained on the data present in the world today, it naturally also modeled the bias present in the data. For example, a prompt for a builder will most likely return images for males while a prompt for a flight attendant will return images for females. You can read more about it here.
So there you have it, now you know how DALL.E.2 works. The API is now in Open Beta and you can get access by joining the waitlist. I will link all the white papers as well as articles I have referred to for writing this post.
That’s it for this issue. I hope you found this article interesting. Until next time!
PS:
Happy Engineers’ Day :)

Reference Articles:
Blog by Aditya Ramesh(Project Lead)
TDS Blog: dall-e-2-explained-the-promise-and-limitations-of-a-revolutionary
An article I found interesting: About the perils of getting too comfortable with safety from Nietzsche
A podcast I found interesting: Joe Rogan - Ryan Holiday: On Stoicism